Re: Heiß, heißer, FujiNet
von tschak909 » So 19. Jul 2020, 02:19#FujiNet #Atari8bit Hallo an alle, die dies lesen, und die vielleicht in der Lage sind, sich einzustimmen:
Ich versuche derzeit, einige Teile des N:-Geräts zu überdenken, solange ich das noch kann (während fast niemand es tatsächlich benutzt).
Das N:-Gerät besteht aus zwei Teilen: Der Handler auf dem Atari, der CIO in SIO umwandelt. Und die Firmware, die SIO in Aktionen auf dem ESP32 umwandelt.
Dies ist von grundlegender Bedeutung, da SIO blockbasiert und CIO zeichenbasiert ist. Um die Diskussion vorerst zu vereinfachen, spreche ich nur über die SIO-Schicht.
DIE SIO-SCHICHT:
Sie können die SIO-Befehle für das N: Gerät hier sehen: https://github.com/FujiNetWIFI/fujinet- ... 1-to-%2478
SIO ist Halbduplex. Sie verarbeitet Daten jeweils nur in einer Richtung, und obwohl es in der Befehlsstruktur ein Feld gibt, das an den Atari gesendet wird, um zu sagen, wie viele Bytes übertragen werden müssen, wird dies nicht als Teil des Befehlsrahmens entweder an oder von FujiNet übermittelt, was wir für READ- und WRITE-Operationen benötigen. Die beiden Bytes AUX1 und AUX2 hingegen schon. Wir müssen also duplizieren, was im DBYT-Feld in den Feldern AUX1 und AUX2 steht, so dass sie als Teil des Befehlsrahmens erscheinen und daher von der Firmware abgefangen werden können.
OPEN - stellt eine Protokollverbindung her, die Nutzlast geht an das FujiNet, und diese Nutzlast ist die N: Dateispezifikation. AUX1 wird zumindest zum offenen Modus, Bit 2 und 3 sind für Lesen und Schreiben bzw. durch den CIO reserviert, so dass wir diese spiegeln müssen.
In OPEN wird AUX2 zum Modus TRANSLATION, d.h. wie übersetzen wir eine Ende-der-Zeile-Sequenz? Derzeit: 0 = keine Übersetzung, Bit 0 übersetzt CR, Bit 1 übersetzt LF, wenn also die Bits 0 und 1 gesetzt sind, dann werden CR/LF zu und von den beiden Endpunkten übersetzt. Wenn beide CR/LF übersetzt werden, wird die Sache komplizierter, denn entweder wird ein Byte HINZUFÜGEN (im Falle der Konvertierung eines einzelnen EOL-Bytes in CR/LF-Bytes) oder ein Byte UNTERZIEHEN (im Falle der Konvertierung von CR/LF-Bytes in ein einzelnes EOL-Byte). Erinnern Sie sich, dass wir im Voraus festgelegt haben, wie viele Bytes zu lesen/schreiben sind?
Wenn ein STATUS-Befehl gesendet wird, werden vier Bytes zurückgegeben. BL BH CO ER, BL und BH sind die Low- und High-Bytes der Anzahl der verfügbaren Bytes (bis zu 65535), während CO verbunden ist (1 = verbunden, 0 = getrennt), und ER der Fehlercode ist, der an den CIO-Handler übergeben wird.
Nehmen wir also an, wir lesen Daten von einem HTTP-Endpunkt:
OPEN N:HTTP://www.google.com/
und in einer Schleife:
```
STATUS();
while (status.bytesVerfügbar>0)
{
READ(buf); // Verringert die Anzahl der verfügbaren Bytes.
verarbeiten(buf);
STATUS();
}
```
Als Teil der Schleife führen wir also einen Status durch, um zu sehen, wie viele Bytes verfügbar sind.
Der WEG, auf dem ich mich derzeit mit der Übersetzung befasse, besteht darin, sie buchstäblich zu fälschen, wobei die gleiche Anzahl von Bytes beibehalten wird:
Wenn CR, dann wird EOL in CR übersetzt, CR wird in EOL übersetzt.
Wenn LF, dann wird EOL in LF übersetzt, LF wird in EOL übersetzt.
Wenn CR/LF, dann wird der Sendepuffer um 1 vergrößert (und die Länge des Sendepuffers um 1 erhöht), und EOL wird zu CR, wobei LF unmittelbar danach eingefügt wird, während beim Empfang CR zu einem SPACE wird, während LF zum EOL wird.
Dadurch braucht der Empfangspuffer seine Größe nicht zu ändern. Ist dies eine schlechte Idee?
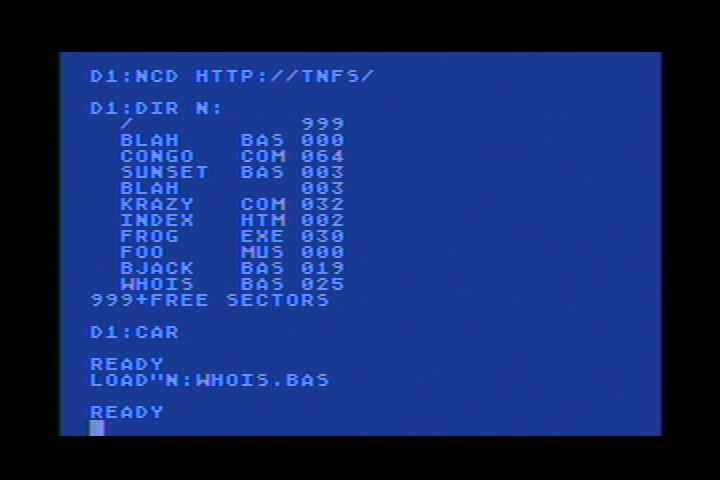
Eine Variante davon ist die Übersetzung von Verzeichnisdaten für Netzwerk-Dateisystem-Endpunkte. Sie können im OPEN-Aufruf angeben, ob Sie das Verzeichnis lesen möchten (aux1=6), aber jedes Netzwerkprotokoll führt ein Dateiverzeichnis anders aus und stellt eine Liste von Objekten in einer völlig anderen Syntax dar.
Während wir in einigen Fällen die Daten so anzeigen könnten, wie sie sind (z.B. von FTP), erwarten eine Reihe von Atari-Programmen (wie z.B. (AtariWriter) etwas, das wie das Atari-DOS-Diskettenverzeichnis aussieht. Aus diesem Grund verwenden selbst DOS-Systeme wie SpartaDOS standardmäßig ein Verzeichnisverzeichnis, das wie Atari-DOS aussieht. Das bedeutet, dass es derzeit Code in der Firmware gibt, um die Verzeichnisdaten, die von einem Protokoll zurückkommen, in etwas zu übersetzen, das wie ein DOS-2-Verzeichnis aussieht. Gegenwärtig bedeutet dies auch, dass das IST-Lesen von Verzeichnisdaten im STATUS-Aufruf erfolgt, wobei die Daten in den Empfangspuffer geleert werden, während READ den RECEIVE-Puffer auf den Atari leert und ihn anschließend für den nächsten Statusaufruf löscht.
Damit stellt sich die Frage: Gibt es einen besseren Weg? Gegenwärtig besteht der CIO-Handler auf dem Atari aus etwa 1000 Byte Code, mit 256 Byte Puffer darüber (also 1,3K im gesamten Speicherverbrauch). Er ist klein, weil alles auf dem ESP passiert, und der Handler alles durchlässt (mit einigen kleinen Ausnahmen). Die CR/LF-Übersetzung könnte z.B. im CIO-Handler auf den Atari verschoben werden, wobei etwa 40 oder so Bytes Code hinzugefügt werden, aber wie sollten wir Dinge wie die Dateiverzeichnis-Übersetzung handhaben? Ist die Handhabung im Statusaufruf der einzig vernünftige Weg, dies wirklich zu tun?
Gedanken?
Ich versuche derzeit, einige Teile des N:-Geräts zu überdenken, solange ich das noch kann (während fast niemand es tatsächlich benutzt).
Das N:-Gerät besteht aus zwei Teilen: Der Handler auf dem Atari, der CIO in SIO umwandelt. Und die Firmware, die SIO in Aktionen auf dem ESP32 umwandelt.
Dies ist von grundlegender Bedeutung, da SIO blockbasiert und CIO zeichenbasiert ist. Um die Diskussion vorerst zu vereinfachen, spreche ich nur über die SIO-Schicht.
DIE SIO-SCHICHT:
Sie können die SIO-Befehle für das N: Gerät hier sehen: https://github.com/FujiNetWIFI/fujinet- ... 1-to-%2478
SIO ist Halbduplex. Sie verarbeitet Daten jeweils nur in einer Richtung, und obwohl es in der Befehlsstruktur ein Feld gibt, das an den Atari gesendet wird, um zu sagen, wie viele Bytes übertragen werden müssen, wird dies nicht als Teil des Befehlsrahmens entweder an oder von FujiNet übermittelt, was wir für READ- und WRITE-Operationen benötigen. Die beiden Bytes AUX1 und AUX2 hingegen schon. Wir müssen also duplizieren, was im DBYT-Feld in den Feldern AUX1 und AUX2 steht, so dass sie als Teil des Befehlsrahmens erscheinen und daher von der Firmware abgefangen werden können.
OPEN - stellt eine Protokollverbindung her, die Nutzlast geht an das FujiNet, und diese Nutzlast ist die N: Dateispezifikation. AUX1 wird zumindest zum offenen Modus, Bit 2 und 3 sind für Lesen und Schreiben bzw. durch den CIO reserviert, so dass wir diese spiegeln müssen.
In OPEN wird AUX2 zum Modus TRANSLATION, d.h. wie übersetzen wir eine Ende-der-Zeile-Sequenz? Derzeit: 0 = keine Übersetzung, Bit 0 übersetzt CR, Bit 1 übersetzt LF, wenn also die Bits 0 und 1 gesetzt sind, dann werden CR/LF zu und von den beiden Endpunkten übersetzt. Wenn beide CR/LF übersetzt werden, wird die Sache komplizierter, denn entweder wird ein Byte HINZUFÜGEN (im Falle der Konvertierung eines einzelnen EOL-Bytes in CR/LF-Bytes) oder ein Byte UNTERZIEHEN (im Falle der Konvertierung von CR/LF-Bytes in ein einzelnes EOL-Byte). Erinnern Sie sich, dass wir im Voraus festgelegt haben, wie viele Bytes zu lesen/schreiben sind?
Wenn ein STATUS-Befehl gesendet wird, werden vier Bytes zurückgegeben. BL BH CO ER, BL und BH sind die Low- und High-Bytes der Anzahl der verfügbaren Bytes (bis zu 65535), während CO verbunden ist (1 = verbunden, 0 = getrennt), und ER der Fehlercode ist, der an den CIO-Handler übergeben wird.
Nehmen wir also an, wir lesen Daten von einem HTTP-Endpunkt:
OPEN N:HTTP://www.google.com/
und in einer Schleife:
```
STATUS();
while (status.bytesVerfügbar>0)
{
READ(buf); // Verringert die Anzahl der verfügbaren Bytes.
verarbeiten(buf);
STATUS();
}
```
Als Teil der Schleife führen wir also einen Status durch, um zu sehen, wie viele Bytes verfügbar sind.
Der WEG, auf dem ich mich derzeit mit der Übersetzung befasse, besteht darin, sie buchstäblich zu fälschen, wobei die gleiche Anzahl von Bytes beibehalten wird:
Wenn CR, dann wird EOL in CR übersetzt, CR wird in EOL übersetzt.
Wenn LF, dann wird EOL in LF übersetzt, LF wird in EOL übersetzt.
Wenn CR/LF, dann wird der Sendepuffer um 1 vergrößert (und die Länge des Sendepuffers um 1 erhöht), und EOL wird zu CR, wobei LF unmittelbar danach eingefügt wird, während beim Empfang CR zu einem SPACE wird, während LF zum EOL wird.
Dadurch braucht der Empfangspuffer seine Größe nicht zu ändern. Ist dies eine schlechte Idee?
Eine Variante davon ist die Übersetzung von Verzeichnisdaten für Netzwerk-Dateisystem-Endpunkte. Sie können im OPEN-Aufruf angeben, ob Sie das Verzeichnis lesen möchten (aux1=6), aber jedes Netzwerkprotokoll führt ein Dateiverzeichnis anders aus und stellt eine Liste von Objekten in einer völlig anderen Syntax dar.
Während wir in einigen Fällen die Daten so anzeigen könnten, wie sie sind (z.B. von FTP), erwarten eine Reihe von Atari-Programmen (wie z.B. (AtariWriter) etwas, das wie das Atari-DOS-Diskettenverzeichnis aussieht. Aus diesem Grund verwenden selbst DOS-Systeme wie SpartaDOS standardmäßig ein Verzeichnisverzeichnis, das wie Atari-DOS aussieht. Das bedeutet, dass es derzeit Code in der Firmware gibt, um die Verzeichnisdaten, die von einem Protokoll zurückkommen, in etwas zu übersetzen, das wie ein DOS-2-Verzeichnis aussieht. Gegenwärtig bedeutet dies auch, dass das IST-Lesen von Verzeichnisdaten im STATUS-Aufruf erfolgt, wobei die Daten in den Empfangspuffer geleert werden, während READ den RECEIVE-Puffer auf den Atari leert und ihn anschließend für den nächsten Statusaufruf löscht.
Damit stellt sich die Frage: Gibt es einen besseren Weg? Gegenwärtig besteht der CIO-Handler auf dem Atari aus etwa 1000 Byte Code, mit 256 Byte Puffer darüber (also 1,3K im gesamten Speicherverbrauch). Er ist klein, weil alles auf dem ESP passiert, und der Handler alles durchlässt (mit einigen kleinen Ausnahmen). Die CR/LF-Übersetzung könnte z.B. im CIO-Handler auf den Atari verschoben werden, wobei etwa 40 oder so Bytes Code hinzugefügt werden, aber wie sollten wir Dinge wie die Dateiverzeichnis-Übersetzung handhaben? Ist die Handhabung im Statusaufruf der einzig vernünftige Weg, dies wirklich zu tun?
Gedanken?